Mixed-Precision Methods+
Summary
Computational precision and the accuracy of the final result have a complicated, non-monotonic relation, so that in general an increase of precision can lead to a decrease of accuracy. While this deteriorating effect of increased precision occurs rather seldom in practice, the non-linear relation often leads to the situation where the accuracy improves differently depending on which part of the algorithm uses higher computational precision. Numerical analysis methods provide knowledge about these relations, and this can be exploited by reducing the computational precision in less sensitive parts of the algorithm and increasing it in the critical ones. This leads to a mixed precision method, which utilizes different computational precision for different parts of the algorithm.
The above idea is particularly attractive for parallel devices with very high single floating point performance, e.g. Graphics Processor Unit (GPU), Field Programmable Gate Arrays (FPGAs), Cell Broadband Engine (Cell BE), Clearspeed’s CSX600, AGEIA’s PhysX. The low precision computations can be executed very quickly in parallel, while the fewer high precision parts of the algorithm that are necessary to obtain the desired accuracy, may be computed in a slower mode on the same device, or can be delegated to the host CPU.
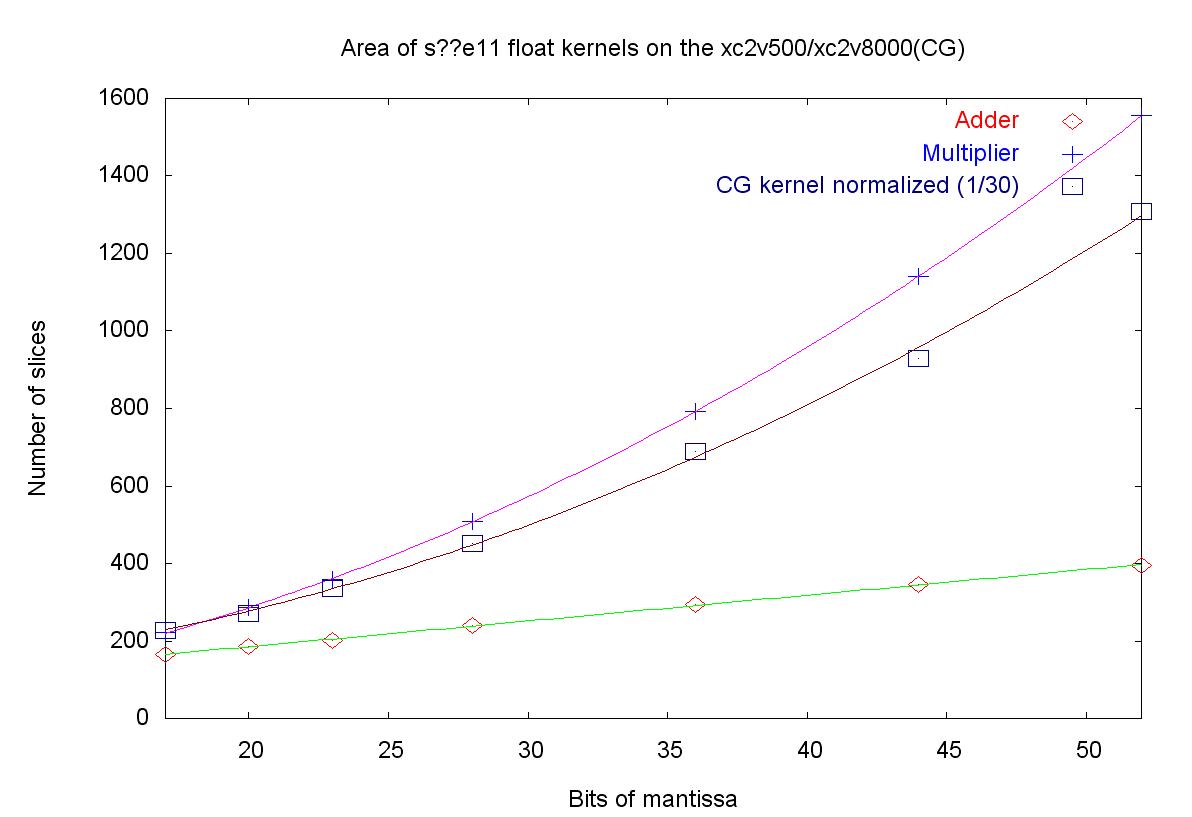
Similar to theory, non-linearities are also present on the hardware level when dealing with different precisions. While a hardware adder grows linearly in size with the operands, a multiplier grows quadratically, see Figure 1. This means that four 32-bit integer multipliers occupy the same area as one 64-bit integer multiplier. For floating point numbers the exact relation depends on the ratio of the exponent to the mantissa bits but in principle remains valid; Figure 1 shows floating point adders and multipliers. However, this quadratic advantage can only be achieved with reconfigurable devices, like FPGAs, because the four 32-bit multipliers need twice as many input bit-lines as one 64-bit multiplier, and on hardwired chips, like CPUs, the data paths are fixed. Therefore, CPUs offer only a linear advantage when halving the size of the number format, e.g. SSE supports 2 double precision or 4 single precision operations.
Hardwired chips can neither reconfigure a higher precision floating point unit and thus have a maximum hardware supported precision, e.g. a GPU offers only single float precision. As any device with lower precision hardware, the GPU can emulate double precision operations, but this requires at least tenfold more operations than the corresponding single float operation. In theory this factor can be reduced to four as above, but because of the hardwired units and data paths, an emulation is always more expensive than the quadratic costs encountered in hardware configurations.
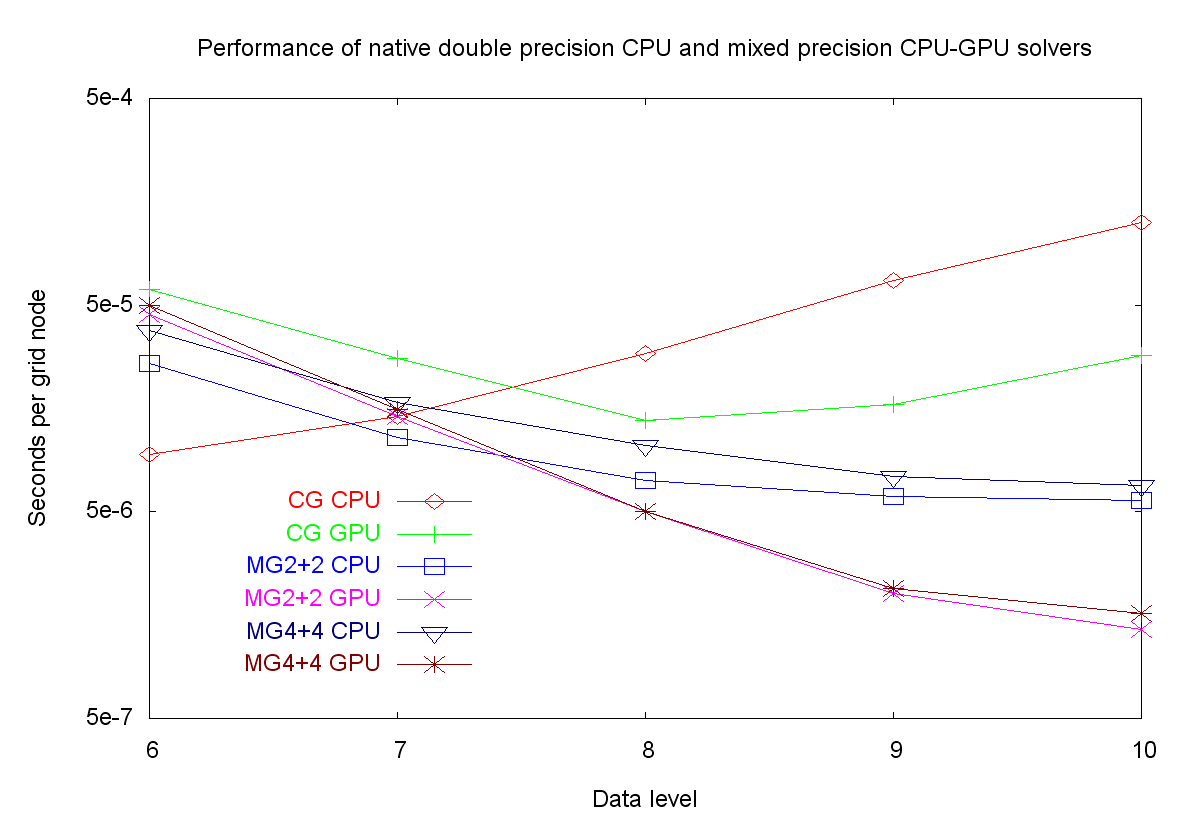
We have performed a detailed comparison of sparse iterative solvers (CG and MG) with native-, emulated- and mixed-precision [4]. This also offers a survey of similar approaches and summarizes our previous work focused specifically on the GPU [1] and FPGA [2]. General, non-linear iterative schemes can also benefit from mixed precision methods [3]. On double precision capable GPUs the benefits of mixed-precision methods still apply and result in almost doubled performance against pure double precision computations, as described in the Balanced Geometric Multigrid project.
Figures
Linear area growth of an adder, the quadratic of a multiplier, and the slower quadratic growth of a conjugate gradient solver in a FPGA (smaller is better).
Comparison of conjugate gradient (CG) and multigrid (MG) solvers with double and mixed-precision (smaller is better).
Publications
- Performance and accuracy of hardware-oriented native-, emulated- and mixed-precision solvers in FEM simulationsInternational Journal of Parallel, Emergent and Distributed Systems (IJPEDS), Special issue: Applied parallel computing, 22(4), 221-256, Taylor & Francis, 2007
@article{Goddeke_performance_2007, author = {Göddeke, Dominik and Strzodka, Robert and Turek, Stefan}, title = {Performance and accuracy of hardware-oriented native-, emulated- and mixed-precision solvers in FEM simulations}, year = {2007}, journal = {International Journal of Parallel, Emergent and Distributed Systems (IJPEDS), Special issue: Applied parallel computing}, volume = {22}, number = {4}, pages = {221-256}, publisher = {Taylor \& Francis}, url = {https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=7874fe45c9a52e42c15e072695961cfc4db40072} } - Pipelined Mixed Precision Algorithms on FPGAs for Fast and Accurate PDE Solvers from Low Precision Components14th IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM 2006), 24-26 April 2006, Napa, CA, USA, Proceedings, 259–270, IEEE Computer Society, 2006
@inproceedings{DBLP:conf/fccm/Strzodka_pipelined_2006, author = {Strzodka, Robert and Göddeke, Dominik}, title = {Pipelined Mixed Precision Algorithms on FPGAs for Fast and Accurate {PDE} Solvers from Low Precision Components}, booktitle = {14th {IEEE} Symposium on Field-Programmable Custom Computing Machines {(FCCM} 2006), 24-26 April 2006, Napa, CA, USA, Proceedings}, pages = {259--270}, publisher = {{IEEE} Computer Society}, year = {2006}, url = {https://www.mathematik.tu-dortmund.de/lsiii/cms/papers/StrzodkaGoeddeke2006.pdf} doi = {10.1109/FCCM.2006.57}, timestamp = {Fri, 24 Mar 2023 00:00:00 +0100}, } - Mixed Precision Methods for Convergent Iterative Schemes, D-59-60, 2006
@conference{Strzodka_mixed_2006, author = {Strzodka, Robert and Göddeke, Dominik}, title = {Mixed Precision Methods for Convergent Iterative Schemes}, year = {2006}, pages = {D-59-60}, month = may, url = {https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=d57c37eabea47129fe13a1adee052d6ddf9cb428} } - Accelerating Double Precision FEM Simulations with GPUs, 2005
@conference{Goddeke_accelerating_2005, author = {Göddeke, Dominik and Strzodka, Robert and Turek, Stefan}, title = {Accelerating Double Precision FEM Simulations with GPUs}, year = {2005}, month = sep, url = {https://www.mathematik.tu-dortmund.de/lsiii/cms/papers/GoeddekeStrzodkaTurek2005a.pdf} }