Iterative Stencil Computations+
Summary
Iterative stencil computations are ubiquitous in scientific computing and the exponential growth of cores in current processors leads to a bandwidth wall problem where limited off-chip bandwidth severely restricts their performance. In this project we aim at overcoming these problems by new algorithms that scale mainly with the aggregate cache bandwidth rather than the system bandwidth.
Naive implementations of stencil computations suffer heavily from system bandwidth limitations. Various cache blocking techniques have been developed to optimize for the spatial data locality in this case. However, optimization of a single stencil application remains by construction bounded by the peak system bandwidth. In view of the exponentially growing discrepancy between peak system bandwidth and peak computational performance, this is a severe limitation for all current multi-core devices and even more so for future many-core devices.
In order to surpass system bandwidth limitations, we must turn to iterative stencil computations and reduce the off-chip traffic significantly by exploiting temporal data locality across multiple iterations with so called time skewing schemes. The idea is to look at the entire iteration space formed by the space and time, the space-time, and divide it into tiles that can be executed quickly in cache. Schemes that explicitly use the cache sizes to construct the tiles are called cache-aware, those that do not use them but can still utilize the caches efficiently are called cache-oblivious.
While time-skewing schemes have been known for a long time their practical benefits were small so far. This project has demonstrated the tremendous performance of efficiently implemented time-skewing schemes with speedups of up to 10x over an optimized naive space-time traversal.
In detail the project has introduced a novel cache-oblivious time-skewing scheme CORALS [1] and a novel cache-aware time-skewing scheme CATS [2]. The latter can be cast into a particularly simple form, that allows to gain most of the benefits with little code complexity [3]. It also possesses certain invariance properties that allow to compare and predict the performance of iterative stencil computations on past, current and future architectures [4]. Finally the schemes have been enhanced to nuCORALS and nuCATS by also accounting for the characteristics of NUMA systems [5].
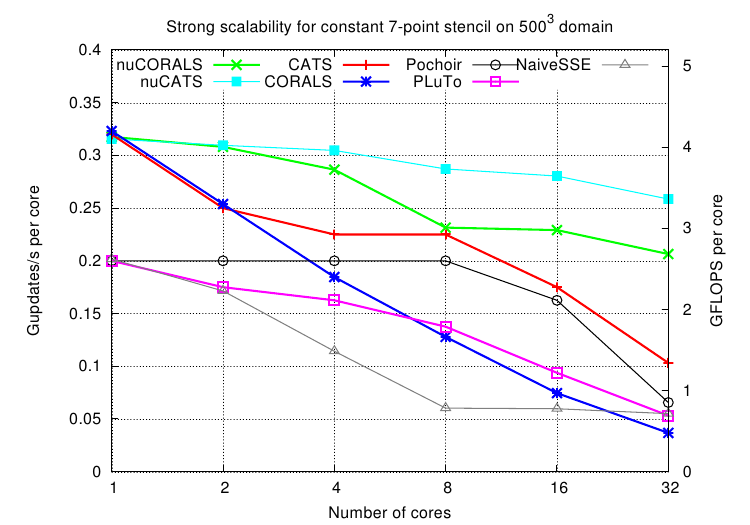
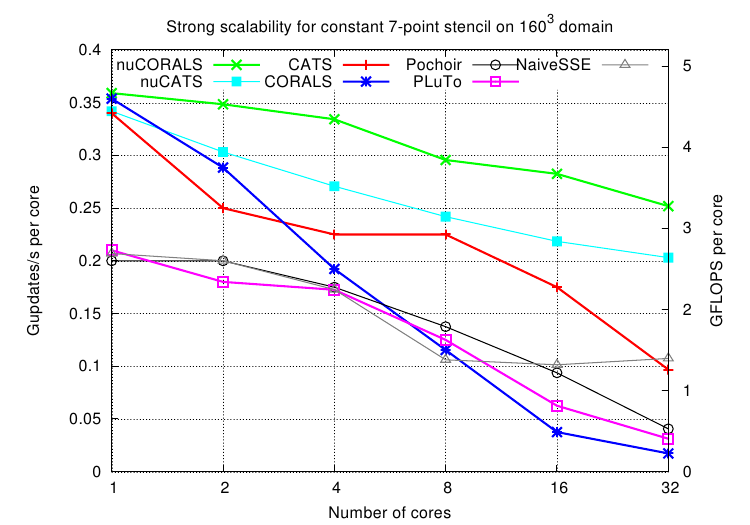
The performance results are impressive (Fig. 3), scaling well with the aggregate cache bandwidth of all cores rather than with the system bandwidth that does not increase automatically with the number of cores.
Figures
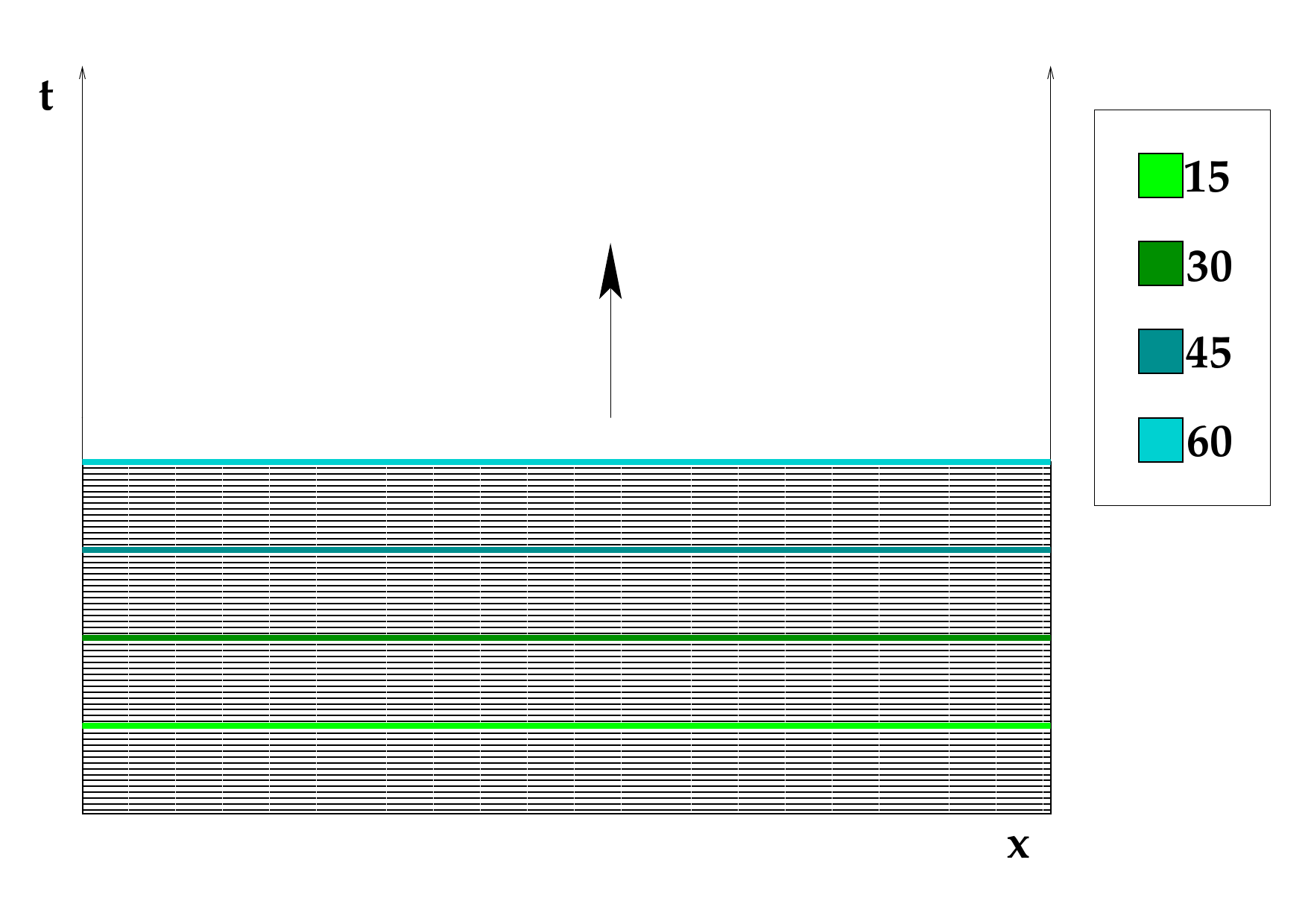
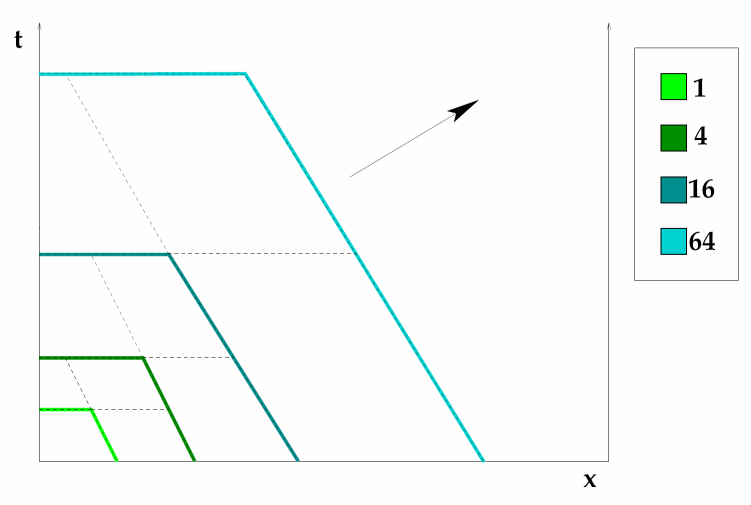
On the left naive space-time traversal. The entire spatial domain executes one timestep after another in sync. The progress of the space-time coverage is shown in color. On the right hierarchical, cache oblivious space-time traversal. Different parts of the spatial domain progress in time at different speeds. Only at the end the entire spatial domain reaches the same timestep [1].
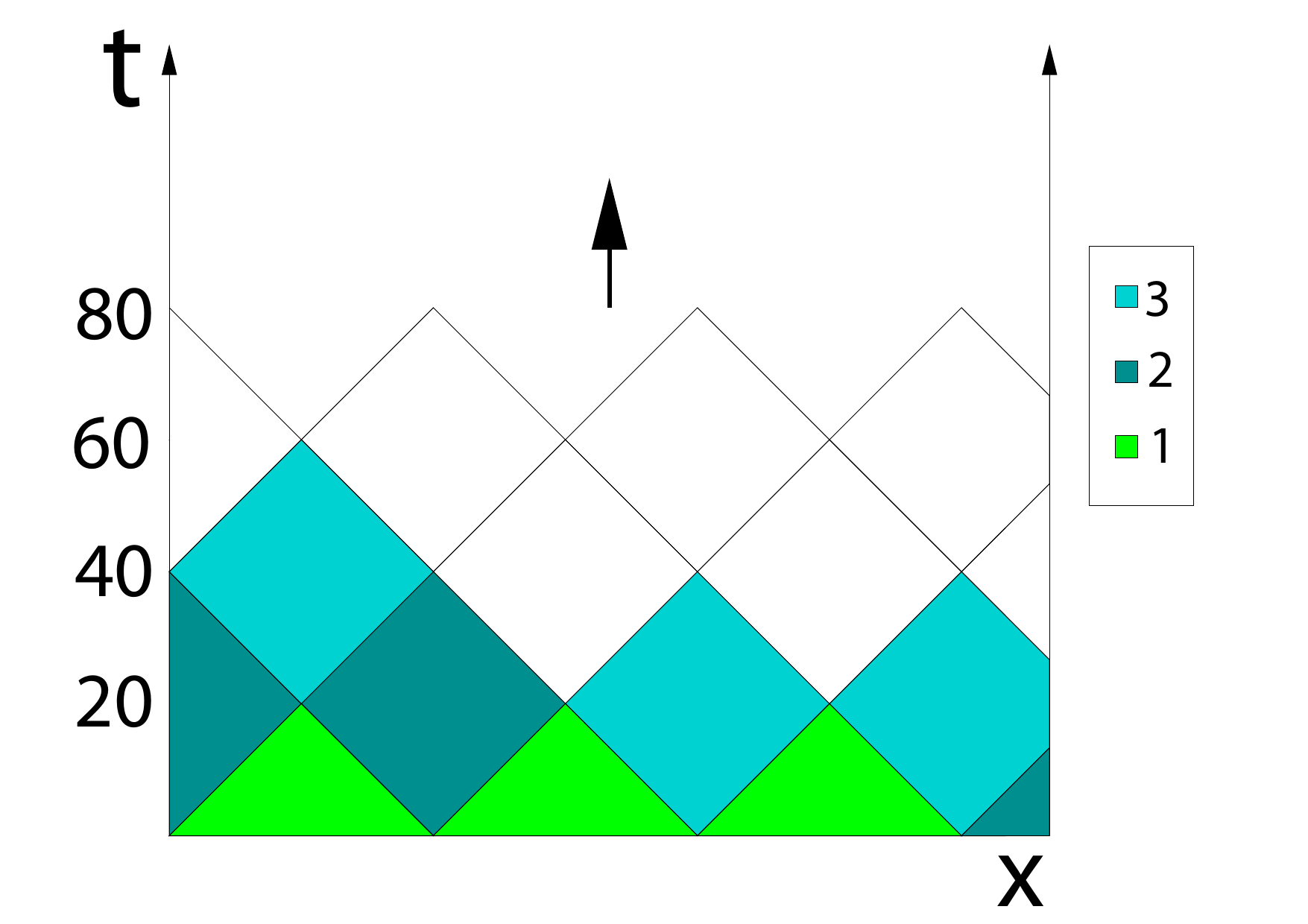
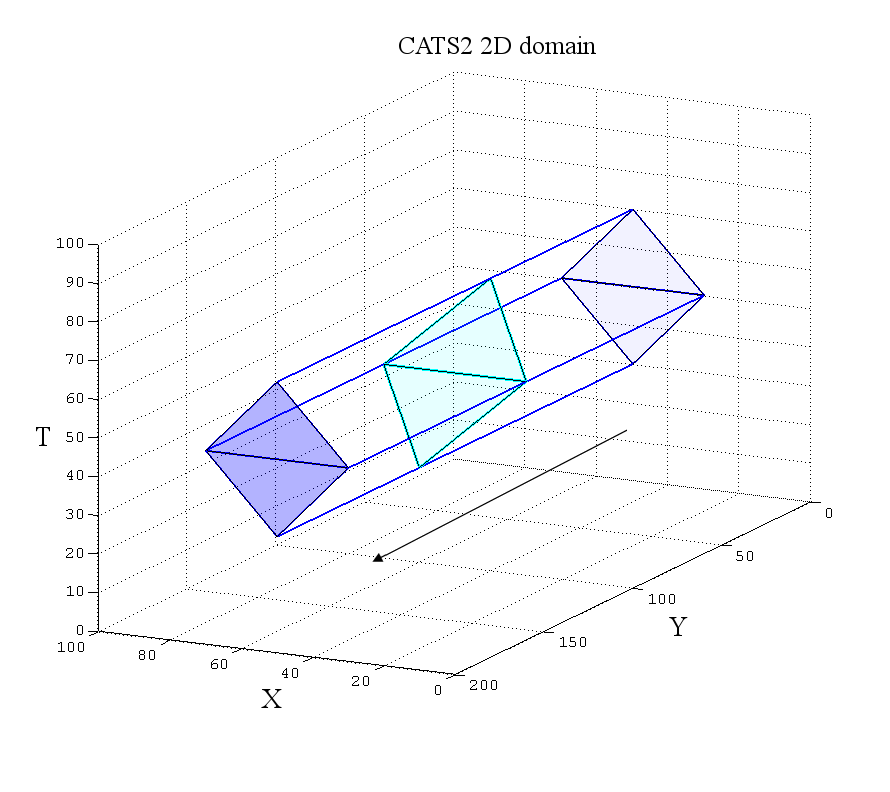
Cache-aware space-time traversal with diamonds [2]. On the left we see the parallel processing of diamonds by three threads with local synchronization between the diamonds. On the right the projection view from the left is expanded into a 3D space-time, showing one diamond-tube with a skewed traversal surface.
Constant stencil strong scalability for 1 to 32 threads on a 500^3 (on the left) and 160^3 (on the right) domain of doubles and 100 timesteps on the Xeon X7550 (4 sockets with 8 cores at 2.0 GHz). Comparison with naive NUMA-aware traversal, PluTo locality optimizer 0.7.0 and Pochoir stencil compiler 0.5.
Publications
- NUMA Aware Iterative Stencil Computations on Many-Core Systems26th IEEE International Parallel and Distributed Processing Symposium, IPDPS 2012, Shanghai, China, May 21-25, 2012, 461–473, IEEE Computer Society, 2012
@inproceedings{DBLP:conf/ipps/Shaheen_numa_2012, author = {Shaheen, Mohammed and Strzodka, Robert}, title = {{NUMA} Aware Iterative Stencil Computations on Many-Core Systems}, booktitle = {26th {IEEE} International Parallel and Distributed Processing Symposium, {IPDPS} 2012, Shanghai, China, May 21-25, 2012}, pages = {461--473}, publisher = {{IEEE} Computer Society}, year = {2012}, url = {https://www.researchgate.net/profile/Mohammed-Shaheen-3/publication/261355856_NUMA_Aware_Iterative_Stencil_Computations_on_Many-Core_Systems/links/5a86bdffaca272017e56d964/NUMA-Aware-Iterative-Stencil-Computations-on-Many-Core-Systems.pdf} doi = {10.1109/IPDPS.2012.50}, timestamp = {Fri, 24 Mar 2023 00:00:00 +0100}, } - Cache Accurate Time Skewing in Iterative Stencil ComputationsInternational Conference on Parallel Processing, ICPP 2011, Taipei, Taiwan, September 13-16, 2011, 571–581, IEEE Computer Society, 2011
@inproceedings{DBLP:conf/icpp/Strzodka_cache_2011, author = {Strzodka, Robert and Shaheen, Mohammed and Pajak, Dawid and Seidel, Hans{-}Peter}, editor = {Gao, Guang R. and Tseng, Yu{-}Chee}, title = {Cache Accurate Time Skewing in Iterative Stencil Computations}, booktitle = {International Conference on Parallel Processing, {ICPP} 2011, Taipei, Taiwan, September 13-16, 2011}, pages = {571--581}, publisher = {{IEEE} Computer Society}, year = {2011}, url = {https://pure.mpg.de/rest/items/item_3567624/component/file_3591709/content} doi = {10.1109/ICPP.2011.47}, timestamp = {Fri, 24 Mar 2023 00:00:00 +0100}, } - Time skewing made simpleProceedings of the 16th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPOPP 2011, San Antonio, TX, USA, February 12-16, 2011, 295–296, ACM, 2011
@inproceedings{DBLP:conf/ppopp/Strzodka_time_2011, author = {Strzodka, Robert and Shaheen, Mohammed and Pajak, Dawid}, editor = {Cascaval, Calin and Yew, Pen{-}Chung}, title = {Time skewing made simple}, booktitle = {Proceedings of the 16th {ACM} {SIGPLAN} Symposium on Principles and Practice of Parallel Programming, {PPOPP} 2011, San Antonio, TX, USA, February 12-16, 2011}, pages = {295--296}, publisher = {{ACM}}, year = {2011}, url = {https://www.researchgate.net/profile/Mohammed-Shaheen-3/publication/221643682_Time_skewing_made_simple/links/55b8cadc08ae9289a08f44f7/Time-skewing-made-simple.pdf} doi = {10.1145/1941553.1941596}, timestamp = {Sun, 12 Jun 2022 19:46:08 +0200}, } - Impact of System and Cache Bandwidth on Stencil Computation Across Multiple Processor Generations, 2011
@conference{Strzodka_impact_2011, author = {Strzodka, Robert and Shaheen, Mohammed and Pajak, Dawid}, title = {Impact of System and Cache Bandwidth on Stencil Computation Across Multiple Processor Generations}, year = {2011}, url = {https://www.researchgate.net/profile/Mohammed-Shaheen-3/publication/266294016_Impact_of_System_and_Cache_Bandwidth_on_Stencil_Computations_Across_Multiple_Processor_Generations/links/55b8cada08aec0e5f43b792c/Impact-of-System-and-Cache-Bandwidth-on-Stencil-Computations-Across-Multiple-Processor-Generations.pdf} } - Cache oblivious parallelograms in iterative stencil computationsProceedings of the 24th International Conference on Supercomputing, 2010, Tsukuba, Ibaraki, Japan, June 2-4, 2010, 49–59, ACM, 2010
@inproceedings{DBLP:conf/ics/Strzodka_cache_2010, author = {Strzodka, Robert and Shaheen, Mohammed and Pajak, Dawid and Seidel, Hans{-}Peter}, editor = {Boku, Taisuke and Nakashima, Hiroshi and Mendelson, Avi}, title = {Cache oblivious parallelograms in iterative stencil computations}, booktitle = {Proceedings of the 24th International Conference on Supercomputing, 2010, Tsukuba, Ibaraki, Japan, June 2-4, 2010}, pages = {49--59}, publisher = {{ACM}}, year = {2010}, url = {https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=3b1b2273e6d3727219d5cf111b3ba79eb8e8ba1e} doi = {10.1145/1810085.1810096}, timestamp = {Fri, 23 Aug 2019 01:00:00 +0200}, }