GPU-Cluster Computing
Summary
Relatively inexpensive scientific PC clusters have become very popular in recent years and already dominate the TOP 500 list of the fastest computers. Each node of such a cluster can be enhanced with a powerful graphics card forming a GPU-cluster. In this way the peak performance of the system increases enormously without putting much strain on the space or cooling constraints. However, programming of parallel computers is already a demanding task. The inclusion of GPUs components into the nodes of a parallel computer not only requires a different programming model for these devices but also creates a heterogeneous hardware system. This project explores the efficient utilization of such heterogeneous systems for scientific computing.
The focus is both on high performance and high productivity. We enhance the FEM solver package FEAST with GPU functionality in a minimally invasive fashion, with less than 1% of the code basis being affected [1]. Moreover, applications based on FEAST can benefit from the GPU acceleration without any code changes. We explore the large-scale scalability [2] and the practical benefits and limits [3] of this approach in detail.
Figures
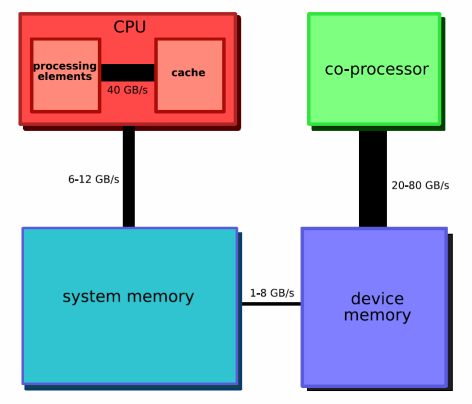
Bandwidth in a typical GPU-node. Algorithms executing on the GPU-cluster must be able to tolerate the enormous discrepancy between the bandwidth on the co-processor board and the bandwidth from board to board that has to pass through the main memory of the hosts.
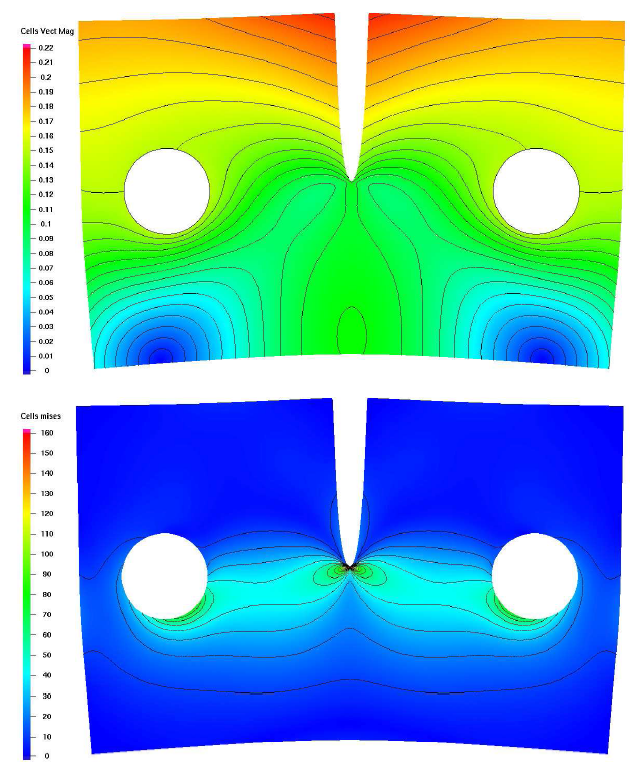
Displacements and van Mises stress of an object under load, computed with FeastSolid on a heterogeneous 16 node cluster using GPUs as scientific co-processors; no code changes, equal accuracy, 2.6x speedup.
Publications
- Co-processor acceleration of an unmodified parallel solid mechanics code with FEASTGPUInt. J. Comput. Sci. Eng., 4(4), 254–269, 2009
@article{DBLP:journals/ijcse/Goddeke_coprocessor_2009, author = {Göddeke, Dominik and Wobker, Hilmar and Strzodka, Robert and Mohd{-}Yusof, Jamaludin and McCormick, Patrick S. and Turek, Stefan}, title = {Co-processor acceleration of an unmodified parallel solid mechanics code with {FEASTGPU}}, journal = {Int. J. Comput. Sci. Eng.}, volume = {4}, number = {4}, pages = {254--269}, year = {2009}, url = {https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=90fc0c4994551bfb32c3d1f42d6bf294dd43edd7} doi = {10.1504/IJCSE.2009.029162}, timestamp = {Mon, 05 Feb 2024 00:00:00 +0100}, } - Using GPUs to improve multigrid solver performance on a clusterInt. J. Comput. Sci. Eng., 4(1), 36–55, 2008
@article{DBLP:journals/ijcse/Goddeke_using_2008, author = {Göddeke, Dominik and Strzodka, Robert and Mohd{-}Yusof, Jamaludin and McCormick, Patrick S. and Wobker, Hilmar and Becker, Christian and Turek, Stefan}, title = {Using GPUs to improve multigrid solver performance on a cluster}, journal = {Int. J. Comput. Sci. Eng.}, volume = {4}, number = {1}, pages = {36--55}, year = {2008}, url = {/content/Goeddeke07.pdf}, doi = {10.1504/IJCSE.2008.021111}, timestamp = {Mon, 05 Feb 2024 00:00:00 +0100}, } - Exploring weak scalability for FEM calculations on a GPU-enhanced clusterParallel Comput., 33(10-11), 685–699, 2007
@article{DBLP:journals/pc/Goddeke_exploring_2007, author = {Göddeke, Dominik and Strzodka, Robert and Mohd{-}Yusof, Jamaludin and McCormick, Patrick S. and Buijssen, Sven H. M. and Grajewski, Matthias and Turek, Stefan}, title = {Exploring weak scalability for {FEM} calculations on a GPU-enhanced cluster}, journal = {Parallel Comput.}, volume = {33}, number = {10-11}, pages = {685--699}, year = {2007}, url = {https://doi.org/10.1016/j.parco.2007.09.002} doi = {10.1016/J.PARCO.2007.09.002}, timestamp = {Mon, 05 Feb 2024 00:00:00 +0100}, }