Balanced Geometric Multigrid+
Summary
A problem specific configuration of a multigrid solver is often the most efficient tool for the solution of sparse linear equation systems. However, neither solvers with best numerical convergence nor solvers with best parallel efficiency are the best choice for an accurate and fast solution in practice. The fastest solvers require a delicate balance between their numerical and hardware characteristics. Balancing both aspects we can even parallelize strong sequential preconditioners with large parallel speedup and hardly any loss in numerical performance. In this way GMG can also solve ill-conditioned systems.
Besides extracting massive parallelism from initially sequential preconditioners there is the second big challenge of fine-grained data access and placement, which is crucial for high performance solvers. We present innovative on-the-fly data sorting techniques for Gauss-Seidel and tridiagonal preconditioners for maximum bandwidth utilization [2]. The entire approach is combined with mixed-precision execution and evaluated extensively on anisotropic grids. In a second step we have parallelized even stronger preconditiner and applied them to yet more ill-conditioned problems, including strong operator anisotropies [1].
Although geometric multigrid is not as flexible as algebraic multigrid, we conclude that with advanced smoothers GMG can also solve many ill-conditioned problems efficiently.
Here we discusses the parallel solution of ill-conditioned problems of about 1 million unknowns on a single GPU. This is an critical builiding block in our library for solving much larger distributed memory problems with GPU-cluster computing.
Figures
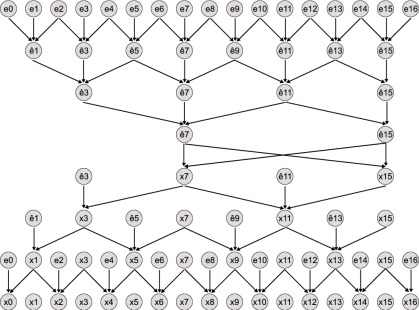
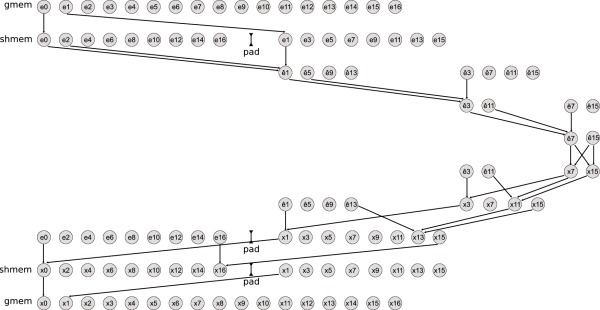
On the left data flow and placement in shared memory in the standard cyclic reduction. Hats stand for updated equations. On the right data placement in our bank-conflict free implementation of cyclic reduction with on-the-fly data rearrangement. The data flow (arrow connections) is exactly the same as on the left, but we have omitted most arrows to improve clarity. In both figures circles in the same column occupy the same memory address, i.e. in-place updates are performed.
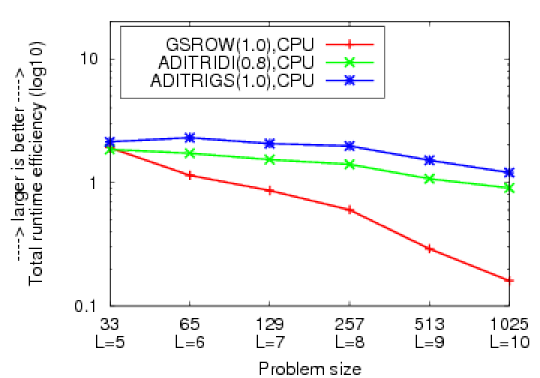
Total runtime efficiency of the GMG solvers with strong smoothers, on the CPU (left) and the GPU (right), for an elliptic problem with operator and domain anisotropies with sizes (2^L+1) x (2^L+1), logarithmic scale.

Current people
- Robert Strzodka (co-PI)
Publications
2011
- Cyclic Reduction Tridiagonal Solvers on GPUs Applied to Mixed Precision MultigridIEEE Transactions on Parallel and Distributed Systems (TPDS), Special Issue: High Performance Computing with Accelerators, 22(1), 22-32, IEEE Computer Society, 2011
@article{Goddeke_cyclic_2011, author = {Göddeke, Dominik and Strzodka, Robert}, title = {Cyclic Reduction Tridiagonal Solvers on GPUs Applied to Mixed Precision Multigrid}, year = {2011}, journal = {IEEE Transactions on Parallel and Distributed Systems (TPDS), Special Issue: High Performance Computing with Accelerators}, volume = {22}, number = {1}, pages = {22-32}, month = jan, publisher = {IEEE Computer Society}, url = {https://www.mathematik.tu-dortmund.de/papers/GoeddekeStrzodka2010.pdf} doi = {10.1109/TPDS.2010.61}, }
2010
- Mixed-Precision GPU-Multigrid Solvers with Strong SmoothersChapman and Hall / CRC computational science seriesScientific Computing with Multicore and Accelerators, 131–147, CRC Press / Taylor & Francis, 2010
@incollection{DBLP:books/tf/10/Goddeke_mixed_2010, author = {Göddeke, Dominik and Strzodka, Robert}, editor = {Kurzak, Jakub and Bader, David A. and Dongarra, Jack J.}, title = {Mixed-Precision GPU-Multigrid Solvers with Strong Smoothers}, booktitle = {Scientific Computing with Multicore and Accelerators}, series = {Chapman and Hall / {CRC} computational science series}, pages = {131--147}, publisher = {{CRC} Press / Taylor {\&} Francis}, year = {2010}, url = {https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=ac25309861ee169c1797e66cbf34f2b88b05c30d} doi = {10.1201/B10376-11}, timestamp = {Sat, 19 Oct 2019 19:02:58 +0200}, }