GPGPU Scientific Computing
Summary
Both Graphics Processor Units (GPUs) and Reconfigurable Computing (RC) devices offer high performance on data parallel applications. For regular grids even early GPUs could be used to execute Finite Element PDE solvers [1]. But without floating point numbers the use was restricted to applications with low accuracy requirements such as multimedia processing. The same was true for most RC devices which concentrated on integer processing. Very efficient image processing solvers could be implemented in this way, but the configuration of floating point operations was either not available or too expensive in terms of reconfigurable resources. With the inclusion of optimized floating point processing units into GPUs and RC devices, they now allow to perform more accurate computations. Although the precision is usually still restricted to the single float format, Mixed Precision Methods can perform most of the computations in single precision and still obtain a double precision result.
The main drawback of utilizing the parallel co-processors in scientific computing are the more complex programming models as opposed to micro-processors. RC devices are usually controlled by structural hardware description languages. These languages allow to exploit the full potential of the available parallelism but require a high design effort. GPUs have an easier, temporal programming model, but the potential for scientific computations is obscured by the application programming interface targeted towards graphics applications and computer games. By hiding most of the peculiarities of the graphics system under an abstraction layer, the GPU can be used as a general vector and array processor. This allows to solve various PDE problems in parallel on the GPU, without dealing with the details of graphics programming [3]. For an orientation of the processing paradigm one can even characterize the GPU without any reference to graphics terminology [2]. The abstraction has been successfully extended to GPU-Cluster Computing.
Figures
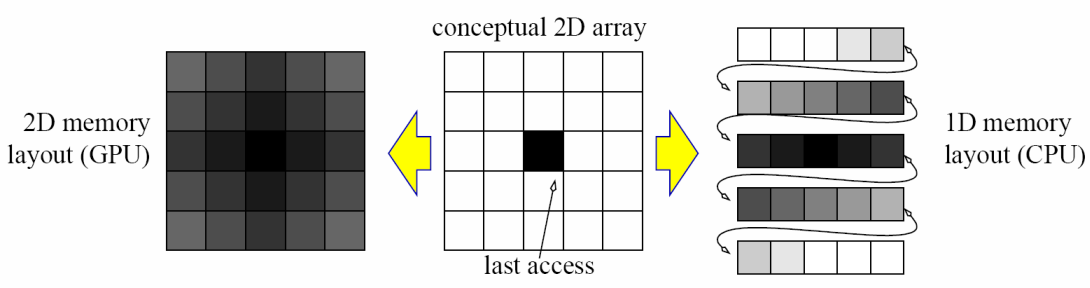
GPUs have a natural 2D memory layout which makes them very suitable for scientific computing on 2D and 3D domains. The darker the color the faster the subsequent access.
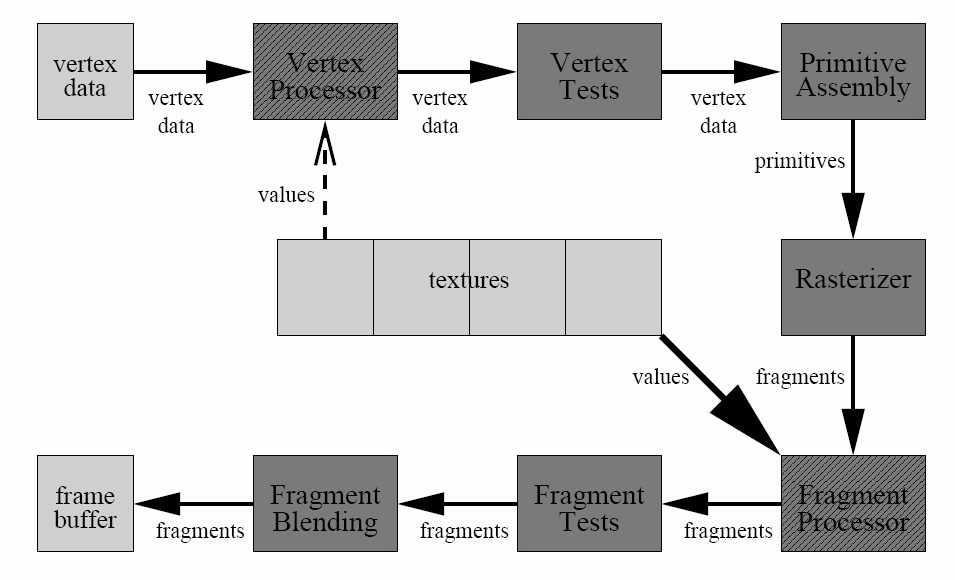
When using the traditional graphics pipeline for scientific computing in GPGPU fashion the most important aspect is the spatially coherent access to data in textures and the massively data parallel processing in the Fragment Processor. All other aspects can be hidden behind library abstractions [3].
Publications
- Scientific computation for simulations on programmable graphics hardwareSimul. Model. Pract. Theory, 13(8), 667–680, 2005
@article{DBLP:journals/simpra/Strzodka_scientific_2005, author = {Strzodka, Robert and Doggett, Michael C. and Kolb, Andreas}, title = {Scientific computation for simulations on programmable graphics hardware}, journal = {Simul. Model. Pract. Theory}, volume = {13}, number = {8}, pages = {667--680}, year = {2005}, url = {https://doi.org/10.1016/j.simpat.2005.08.001} doi = {10.1016/J.SIMPAT.2005.08.001}, timestamp = {Mon, 24 Feb 2020 00:00:00 +0100}, } - Graphics Processor Units: New Prospects for Parallel Computing, 51, 89-134, Springer, 2005
@inbook{Rumpf_graphics_2005, author = {Rumpf, Martin and Strzodka, Robert}, title = {Graphics Processor Units: New Prospects for Parallel Computing}, year = {2005}, volume = {51}, pages = {89-134}, publisher = {Springer}, url = {https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=92f86108a6c5e1a2954e0485ffb5de2543c7405b} } - Hardware efficient PDE solvers in quantized image processingPh. D. thesis, University of Duisburg-Essen, Germany. , 2004
@phdthesis{DBLP:phd/de/Strzodka_hardware_2004, author = {Strzodka, Robert}, title = {Hardware efficient {PDE} solvers in quantized image processing}, school = {University of Duisburg-Essen, Germany}, year = {2004}, url = {https://duepublico2.uni-due.de/receive/duepublico_mods_00005631} urn = {urn:nbn:de:hbz:464-duett-02242005-0002162}, timestamp = {Sat, 17 Jul 2021 01:00:00 +0200}, }