Reconfigurable Computing
Summary
Reconfigurable Computing encompasses many different architectures which allow configurability on the hardware level. The main motivation is to bring together the high performance of hardwired Application Specific Integrated Circuits (ASICs) and the programming flexibility of micro-processors. The architectures offer different compromises between these antipodes, but the focus is often on highly parallel processing optimized for high data throughput rather than low latency response. A popular arrangement of parallel processing elements (PEs) is a tile architecture with a configurable interconnect between the tiles. The functionality of the PEs can range from boolean functions on individual bits to entire processors. In this project we have worked with an FPGA (Field Programmable Gate Arrays) which has fine-grained PEs (4 bit input look-up tables) and a computing array with coarse-grained PEs (24 bit ALUs)
On the relatively small FPGA (XC4085 XLA from Xilinx) we have implemented a solver for the level set equation and use it for segmentation of medical images (Fig. 2, [1]). The FPGA was operated on a low-cost PCI card in a standard PC. The computing array (XPP from PACT) we have used for denoising of images with a non-linear diffusion model (Fig. 4, [3]). Because the actual hardware was not available at first, the configurations were tested with a clock accurate simulator and the results generated with a software simulation.
In view of the memory wall problem, a huge advantage of the free configurability is the possibility to incorporate all sorts of data-flow optimizations and parallelism into the implementation (Fig. 1). In particular deep pipelines can be built which require little bandwidth and execute many operations in parallel (Fig. 3, [2]). So even with the low frequencies of the devices in tens of MHz, a GHz PC can be easily outperformed, since we do not suffer a bandwidth problem and hundred or more operations are performed in each clock cycle in parallel.
The main disadvantage is the more tedious programming models based on hardware description languages and lack of native floating point arithmetic. For image processing, characterized by low precision input, we can gain more parallelism by reducing computational precision according to the input, and therefore reconfigurable computing is popular in this area. In scientific computing configuring double precision floating point arithmetic would consume too many resources. For iterative solvers mixed precision methods solve this problem [4]. However, the programming complexity remains. Therefore, we are interested in high level languages which can efficiently utilize the massive parallelism of reconfigurable devices.
Figures
Fig. 1: Some optimizations available in reconfigurable computing.
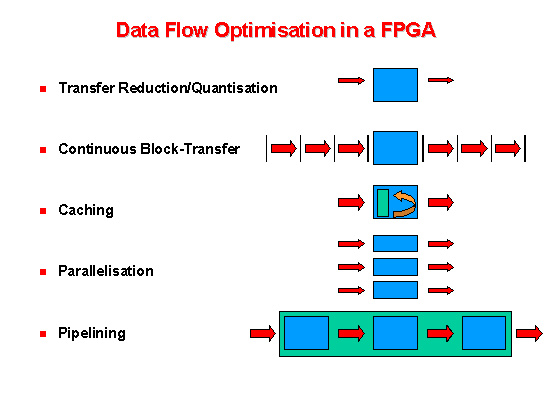
Fig. 2: Segmentation of a brain tumor computed with the FPGA.
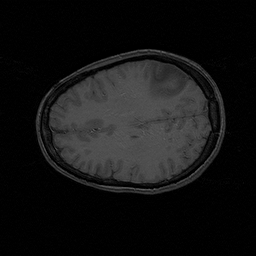
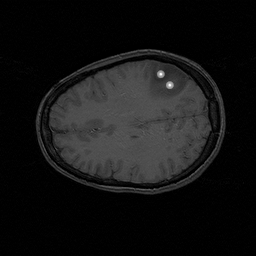

Fig. 3: Configuration of a 3x3 filter for a 2D image in the XPP.
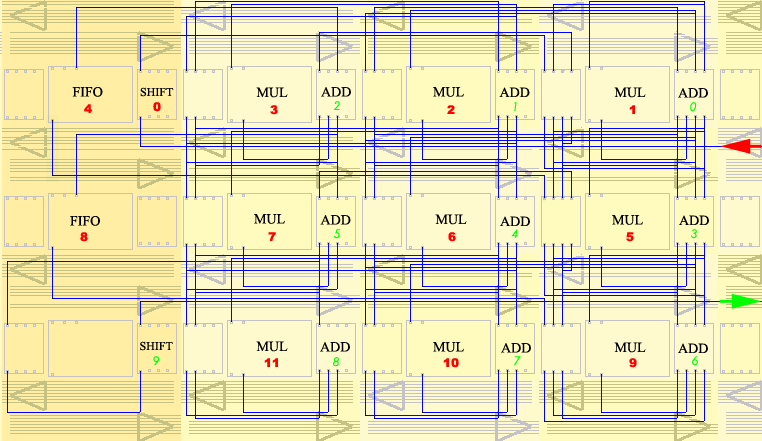
Fig. 4: Non-linear diffusion as implemented on the XPP.



Publications
- Pipelined Mixed Precision Algorithms on FPGAs for Fast and Accurate PDE Solvers from Low Precision Components14th IEEE Symposium on Field-Programmable Custom Computing Machines (FCCM 2006), 24-26 April 2006, Napa, CA, USA, Proceedings, 259–270, IEEE Computer Society, 2006
@inproceedings{DBLP:conf/fccm/Strzodka_pipelined_2006, author = {Strzodka, Robert and Göddeke, Dominik}, title = {Pipelined Mixed Precision Algorithms on FPGAs for Fast and Accurate {PDE} Solvers from Low Precision Components}, booktitle = {14th {IEEE} Symposium on Field-Programmable Custom Computing Machines {(FCCM} 2006), 24-26 April 2006, Napa, CA, USA, Proceedings}, pages = {259--270}, publisher = {{IEEE} Computer Society}, year = {2006}, url = {https://www.mathematik.tu-dortmund.de/lsiii/cms/papers/StrzodkaGoeddeke2006.pdf} doi = {10.1109/FCCM.2006.57}, timestamp = {Fri, 24 Mar 2023 00:00:00 +0100}, } - Hardware efficient PDE solvers in quantized image processingPh. D. thesis, University of Duisburg-Essen, Germany. , 2004
@phdthesis{DBLP:phd/de/Strzodka_hardware_2004, author = {Strzodka, Robert}, title = {Hardware efficient {PDE} solvers in quantized image processing}, school = {University of Duisburg-Essen, Germany}, year = {2004}, url = {https://duepublico2.uni-due.de/receive/duepublico_mods_00005631} urn = {urn:nbn:de:hbz:464-duett-02242005-0002162}, timestamp = {Sat, 17 Jul 2021 01:00:00 +0200}, } - Generalized Distance Transforms and Skeletons in Graphics Hardware6th Joint Eurographics - IEEE TCVG Symposium on Visualization, VisSym 2004, Konstanz, Germany, May 19-21, 2004, 221–230, Eurographics Association, 2004
@inproceedings{DBLP:conf/vissym/Strzodka_generalized_2004, author = {Strzodka, Robert and Telea, Alexandru C.}, editor = {Deussen, Oliver and Hansen, Charles D. and Keim, Daniel A. and Saupe, Dietmar}, title = {Generalized Distance Transforms and Skeletons in Graphics Hardware}, booktitle = {6th Joint Eurographics - {IEEE} {TCVG} Symposium on Visualization, VisSym 2004, Konstanz, Germany, May 19-21, 2004}, pages = {221--230}, publisher = {Eurographics Association}, year = {2004}, url = {https://doi.org/10.2312/VisSym/VisSym04/221-230} doi = {10.2312/VISSYM/VISSYM04/221-230}, timestamp = {Wed, 17 Mar 2021 00:00:00 +0100}, } - Real-Time Motion Estimation and Visualization on Graphics Cards15th IEEE Visualization Conference, IEEE Vis 2004, Austin, TX, USA, October 10-15, 2004, Proceedings, 545–552, IEEE Computer Society, 2004
@inproceedings{DBLP:conf/visualization/Strzodka_realtime_2004, author = {Strzodka, Robert and Garbe, Christoph S.}, title = {Real-Time Motion Estimation and Visualization on Graphics Cards}, booktitle = {15th {IEEE} Visualization Conference, {IEEE} Vis 2004, Austin, TX, USA, October 10-15, 2004, Proceedings}, pages = {545--552}, publisher = {{IEEE} Computer Society}, year = {2004}, url = {/content/Real-time_motion_estimation_and_visualization_on_graphics_cards.pdf}, doi = {10.1109/VISUAL.2004.88}, timestamp = {Thu, 23 Mar 2023 00:00:00 +0100}, } - Real Time Image Processing based on Reconfigurable Hardware Acceleration, 2002
@conference{Klupsch_realtime_2002, author = {Klupsch, Steffen and Ernst, Markus and Huss, Sorin and Rumpf, Martin and Strzodka, Robert}, title = {Real Time Image Processing based on Reconfigurable Hardware Acceleration}, year = {2002}, url = {https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=dceef094b0a8d6192fd6278c16302a6423a92cd8} }