GPGPU Computer Vision
Summary
Similar to image processing, low- and mid-level computer vision applications also allow data parallel processing. However, instead of operating in the same manner on the entire image usually only certain areas are of interest to the application. For an efficient computation it is important to detect them and skip the processing outside of the region of interest. But optimized parallel processing units are poor decision makers. Luckily, the regions of interest are in most cases not randomly distributed but rather spatially coherent. Graphics Processor Units (GPUs) are optimized for the processing of contiguous pixel regions and thus with some modifications we can use their processing power for many computer vision applications.
We apply different strategies concerning the focusing of the computation on certain image areas. One strategy is to include more pixels to the region of interest and thus increase the operation count in favor of spatially coherent regions and a regular memory access pattern. This turned out especially useful on older GPUs which were very poor at branching. The Generalized Hough Transform convolving an object’s contour with a set of edges extracted from a scene has an irregular memory access pattern. By treating the detected edges as an entire image the operation count greatly increases but memory latency of random accesses is avoided. The additional space between the edges can be used to smoothly extend them and thus reduce the required number of contours to be tested (Fig. 1).
Often the region of interest is not global, i.e. different points require the consideration of different regions for processing. In case of the Distance Transform computation the computer has to check the distance to all points of a contour to determine the closest one. Most of these distance computations are unnecessary, since for each point a rough estimation can quickly deliver these parts of the contour which contain the closest point. But this produces data dependent regions of interest, as different points will require the examination of different parts of the contour. A parallel handling of these different regions of interest can be obtained by computing an upper bound on the minimal distance to the contour on a coarse version of the object boundary. These rough bounds can then be used to skip the processing of entire regions during the actual computation (Fig. 2).
Another strategy for the restriction of computation to certain areas is to process the entire image in tiles and skip processing for irrelevant tiles under some condition. Unlike the built-in mechanisms of GPUs the explicit tiling offers better control over the criteria when the processing should stop. For the purpose of motion estimation of humans, for example, it does not make sense to enforce the processing of a tile if only very few pixels contain relevant data. Thus one avoids to compute the motion of irregularities due to noise from the acquisition device or air convection (Fig. 3).
With the increasing support of GPUs for dynamic branching also more diverse parallel work loads will be suitable for hardware acceleration.
Figures
Fig. 1: Generalized Hough Transform for object recognition computed in DirectX8 graphics hardware


Fig. 2: Generalized Distance Transforms, skeletons and Voronoi diagrams computed in DirectX9 graphics hardware.
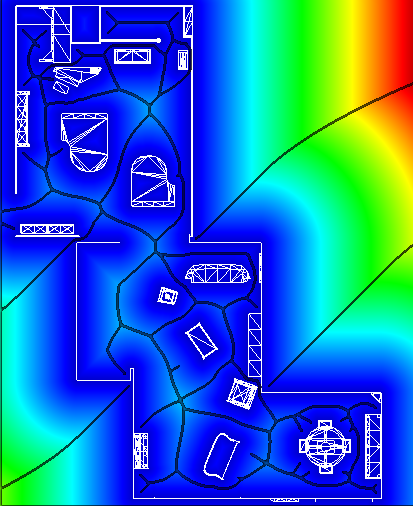
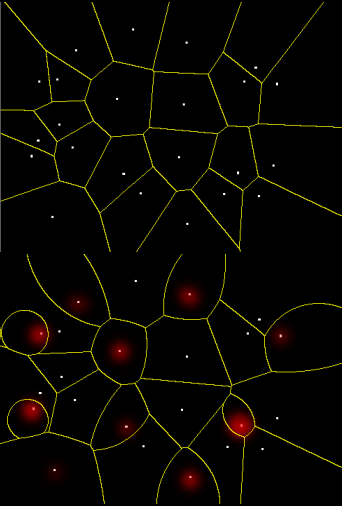
Fig. 3: Motion estimation and feature visualization computed in DirectX9 graphics hardware.


Publications
Code
- Multiscale image based flow visualizationSPIE ProceedingsVisualization and Data Analysis 2006, San Jose, CA, USA, January 15, 2006, 6060, 606001, SPIE, 2006
@inproceedings{DBLP:conf/vda/Telea_multiscale_2006, author = {Telea, Alexandru C. and Strzodka, Robert}, editor = {Erbacher, Robert F. and Roberts, Jonathan C. and Gröhn, Matti T. and Börner, Katy}, title = {Multiscale image based flow visualization}, booktitle = {Visualization and Data Analysis 2006, San Jose, CA, USA, January 15, 2006}, series = {{SPIE} Proceedings}, volume = {6060}, pages = {606001}, publisher = {{SPIE}}, year = {2006}, url = {https://research.rug.nl/files/2829203/2006ProcVDATelea.pdf} doi = {10.1117/12.640425}, timestamp = {Wed, 17 Mar 2021 00:00:00 +0100}, } - Real-Time Motion Estimation and Visualization on Graphics Cards15th IEEE Visualization Conference, IEEE Vis 2004, Austin, TX, USA, October 10-15, 2004, Proceedings, 545–552, IEEE Computer Society, 2004
@inproceedings{DBLP:conf/visualization/Strzodka_realtime_2004, author = {Strzodka, Robert and Garbe, Christoph S.}, title = {Real-Time Motion Estimation and Visualization on Graphics Cards}, booktitle = {15th {IEEE} Visualization Conference, {IEEE} Vis 2004, Austin, TX, USA, October 10-15, 2004, Proceedings}, pages = {545--552}, publisher = {{IEEE} Computer Society}, year = {2004}, url = {/content/Real-time_motion_estimation_and_visualization_on_graphics_cards.pdf}, doi = {10.1109/VISUAL.2004.88}, timestamp = {Thu, 23 Mar 2023 00:00:00 +0100}, } - A graphics hardware implementation of the generalized Hough transform for fast object recognition, scale, and 3D pose detection12th International Conference on Image Analysis and Processing (ICIAP 2003), 17-19 September 2003, Mantova, Italy, 188–193, IEEE Computer Society, 2003
@inproceedings{DBLP:conf/iciap/Strzodka_graphics_2003, author = {Strzodka, Robert and Ihrke, Ivo and Magnor, Marcus A.}, title = {A graphics hardware implementation of the generalized Hough transform for fast object recognition, scale, and 3D pose detection}, booktitle = {12th International Conference on Image Analysis and Processing {(ICIAP} 2003), 17-19 September 2003, Mantova, Italy}, pages = {188--193}, publisher = {{IEEE} Computer Society}, year = {2003}, url = {https://graphics.tu-bs.de/upload/people/magnor/publications/iciap03.pdf} doi = {10.1109/ICIAP.2003.1234048}, timestamp = {Sun, 12 Nov 2023 00:00:00 +0100}, }